Neural CGI
“In this work, published in Science (Open Access version), we introduce the Generative Query Network (GQN), a framework within which machines learn to perceive their surroundings by training only on data obtained by themselves as they move around scenes…The GQN model is composed of two parts: a representation network and a generation network. The representation network takes the agent’s observations as its input and produces a representation (a vector) which describes the underlying scene. The generation network then predicts (‘imagines’) the scene from a previously unobserved viewpoint…The representation network does not know which viewpoints the generation network will be asked to predict, so it must find an efficient way of describing the true layout of the scene as accurately as possible. It does this by capturing the most important elements, such as object positions, colours and the room layout, in a concise distributed representation…The GQN’s generation network can ‘imagine’ previously unobserved scenes from new viewpoints with remarkable precision. When given a scene representation and new camera viewpoints, it generates sharp images without any prior specification of the laws of perspective, occlusion, or lighting. The generation network is therefore an approximate renderer that is learned from data”
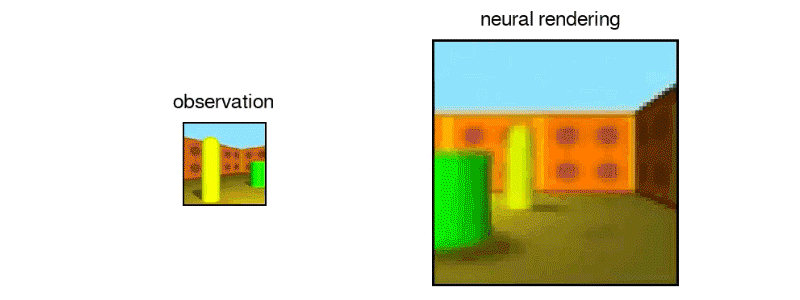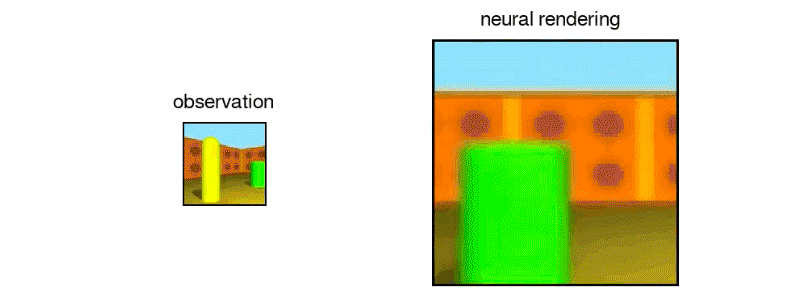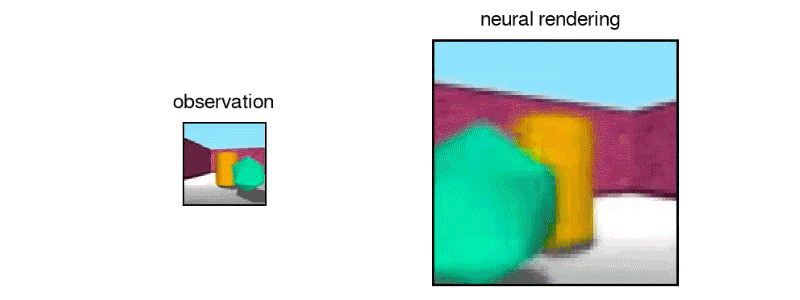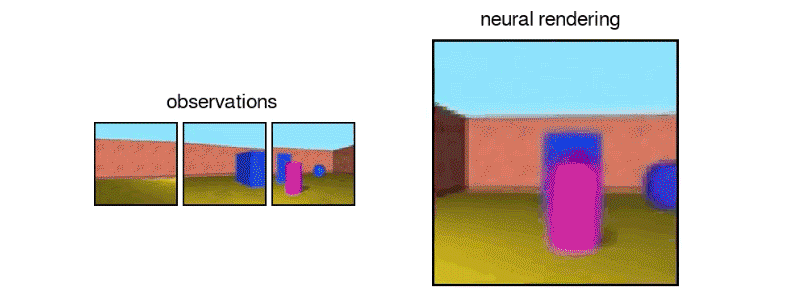
https://deepmind.com/blog/neural-scene-representation-and-rendering/
Neural scene representation and rendering by S. M. Ali Eslami*,†, Danilo Jimenez Rezende†, Frederic Besse, Fabio Viola, Ari S. Morcos, Marta Garnelo, Avraham Ruderman, Andrei A. Rusu, Ivo Danihelka, Karol Gregor, David P. Reichert, Lars Buesing, Theophane Weber, Oriol Vinyals, Dan Rosenbaum, Neil Rabinowitz, Helen King, Chloe Hillier, Matt Botvinick, Daan Wierstra, Koray Kavukcuoglu, Demis Hassabis.
Click to access Neural_Scene_Representation_and_Rendering_preprint.pdf
Could a Neuroscientist Understand a Microprocessor?
Great article where the authors take a microprocessor chip and subject it to the kinds of analyses that we do on brains, to see when they discover true things and when they ‘discover’ misleading results:
http://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1005268
Stochastic computing
One method of computing is to require that all numbers be real values between 0 and 1, and then instead of encoding these numbers into bit streams using binary, represent them with a long stream of random bits which are 1 with probability x, where x is the number being encoded. An advantage is that computations which require many logic gates to implement can implemented more simply (assuming that the randomness in the input bit streams are uncorrelated); eg x*y can be implemented by ANDing the bit streams together, and (x+y)/2 can be implemented by evenly sampling both of the inputs (select about half the bits from x, and the other half of the bits from y, and concatenate all of the selected bits (in any order) to produce the output). Another advantage is that this method is naturally tolerant to noise.
If the circuit is tolerant to noise, power can be saved because circuit elements can be designed to consume less power at the cost of producing noisy results.
A disadvantage is that the numbers of bits needed to represent each number scales exponentially with required precision, as opposed to radix encodings such as binary which scale linearly (eg to represent one of 256 values, you need 8 bits in binary but 256 bits using stochastic computing).
Obviously, this sort of thing is a candidate neural code.
Some links:
- https://en.wikipedia.org/wiki/Stochastic_computing
- https://spectrum.ieee.org/computing/hardware/computing-with-random-pulses-promises-to-simplify-circuitry-and-save-power
- https://www.researchgate.net/profile/Weikang_Qian/publication/224182500_An_Architecture_for_Fault-Tolerant_Computation_with_Stochastic_Logic/links/00b495330bafab0a03000000.pdf
- https://pdfs.semanticscholar.org/120f/1b1c6ed76ca858e1c273ced4b2bfeb7a5a60.pdf
Memory improvement via stimulation of temporal cortex
Stimulation of temporal cortex with electrodes at memory encoding time boosted recall by 15%, in humans.
In the first phase, researchers listened to brain activity while subjects were memorizing nouns. They trained a model to try to predict, based on the brain activity at encoding time, if that word would be remembered or not. In the second phase, researchers ran the model while subjects were memorizing words, and if the model predicted that the word was more than 50% likely to be forgotten, they zapped the brain for 0.5 seconds (through a single pair of adjacent electrodes in the lateral temporal cortex, at amplitudes ranging from 0.5 mA to 1.5 mA (for electrodes deep in the cortex) or 3.5 mA (for the cortical surface) (amplitude was the maximum within this range such that stimulation didn’t appear to cause afterdischarges). Stimulation in this fashion improved recall by 15%. After stimulation, the classifier was more likely to say that the subject would remember the word, which might suggest that the stimulation improved recall by sometimes nudging the brain into a state that the classifier recognized as good for memory encoding.
As an aside, imo one should keep in mind that this doesn’t necessarily mean that this would be a good thing to do every time you are learning something. The way i like to think about this experiment is to imagine that you have some big machine that you don’t know how it works. The machine sometimes makes humming noises and other times it makes sputtering noises. You notice that when it makes the sputtering noise, this correlates somewhat with it not doing its job so well. So, whenever you hear a sputtering noise, you kick it really hard. Sometimes when you kick it, it makes it hum again. You record data and find out that if you kick it when it sputters, that improves output by 15%. That’s very interesting, but does it mean that it’s a good idea to kick the machine whenever it sputters? No — maybe kicking the machine damages it a little (or has some small probability of damaging it sometimes), or maybe the sputtering was something (such as a self-cleaning cycle) that the machine needs to do for its long-term health even at the cost of short-term performance. In other words, there is a clear gain to kicking the machine when it sputters, but it is unknown if there is also a subtle cost.
Youssef Ezzyat, Paul A. Wanda, Deborah F. Levy, Allison Kadel, Ada Aka, Isaac Pedisich, Michael R. Sperling, Ashwini D. Sharan, Bradley C. Lega, Alexis Burks, Robert E. Gross, Cory S. Inman, Barbara C. Jobst, Mark A. Gorenstein, Kathryn A. Davis, Gregory A. Worrell, Michal T. Kucewicz, Joel M. Stein, Richard Gorniak, Sandhitsu R. Das, Daniel S. Rizzuto & Michael J. Kahana. Closed-loop stimulation of temporal cortex rescues functional networks and improves memory.
Gene ‘Arc’ transports mRNA across cells and is required for some forms of plasticity
Also it appears to have evolved from viruses.
Elissa D. Pastuzyn, Cameron E. Day, Rachel B. Kearns, Madeleine Kyrke-Smith, Andrew V. Taibi, John McCormick, Nathan Yoder, David M. Belnap, Simon Erlendsson, Dustin R. Morado, John A.G. Briggs, Cédric Feschotte, Jason D. Shepherd. The Neuronal Gene Arc Encodes a Repurposed Retrotransposon Gag Protein that Mediates Intercellular RNA Transfer
James Ashley, Benjamin Cordy, Diandra Luci, Lee G. Fradkin, Vivian Budnik, Travis Thomson. Retrovirus-like Gag Protein Arc1 Binds RNA and Traffics across Synaptic Boutons
Neural Engineering System Design programme (DARPA funding award announced)
https://www.darpa.mil/news-events/2017-07-10
“The NESD program looks ahead to a future in which advanced neural devices offer improved fidelity, resolution, and precision sensory interface for therapeutic applications,” said Phillip Alvelda, the founding NESD Program Manager. “By increasing the capacity of advanced neural interfaces to engage more than one million neurons in parallel…”
”
- A Brown University team led by Dr. Arto Nurmikko will seek to decode neural processing of speech, focusing on the tone and vocalization aspects of auditory perception. The team’s proposed interface would be composed of networks of up to 100,000 untethered, submillimeter-sized “neurograin” sensors implanted onto or into the cerebral cortex. A separate RF unit worn or implanted as a flexible electronic patch would passively power the neurograins and serve as the hub for relaying data to and from an external command center that transcodes and processes neural and digital signals.
- A Columbia University team led by Dr. Ken Shepard will study vision and aims to develop a non-penetrating bioelectric interface to the visual cortex. The team envisions layering over the cortex a single, flexible complementary metal-oxide semiconductor (CMOS) integrated circuit containing an integrated electrode array. A relay station transceiver worn on the head would wirelessly power and communicate with the implanted device.
- A Fondation Voir et Entendre team led by Drs. Jose-Alain Sahel and Serge Picaud will study vision. The team aims to apply techniques from the field of optogenetics to enable communication between neurons in the visual cortex and a camera-based, high-definition artificial retina worn over the eyes, facilitated by a system of implanted electronics and micro-LED optical technology.
- A John B. Pierce Laboratory team led by Dr. Vincent Pieribone will study vision. The team will pursue an interface system in which modified neurons capable of bioluminescence and responsive to optogenetic stimulation communicate with an all-optical prosthesis for the visual cortex.
- A Paradromics, Inc., team led by Dr. Matthew Angle aims to create a high-data-rate cortical interface using large arrays of penetrating microwire electrodes for high-resolution recording and stimulation of neurons. As part of the NESD program, the team will seek to build an implantable device to support speech restoration. Paradromics’ microwire array technology exploits the reliability of traditional wire electrodes, but by bonding these wires to specialized CMOS electronics the team seeks to overcome the scalability and bandwidth limitations of previous approaches using wire electrodes.
- A University of California, Berkeley, team led by Dr. Ehud Isacoff aims to develop a novel “light field” holographic microscope that can detect and modulate the activity of up to a million neurons in the cerebral cortex. The team will attempt to create quantitative encoding models to predict the responses of neurons to external visual and tactile stimuli, and then apply those predictions to structure photo-stimulation patterns that elicit sensory percepts in the visual or somatosensory cortices, where the device could replace lost vision or serve as a brain-machine interface for control of an artificial limb.
”
See https://www.darpa.mil/attachments/FactsheetNESDKickoffFinal.pdf for more details.
Google/Deepmind/Silver and Huang’s new Go-playing program
There’s some buzz around recent improvements in Go-playing programs. Google made a program that is pretty good against human opponents but it uses 170GPUs and 1200CPUs!
paper: Mastering the Game of Go with Deep Neural Networks and Tree Search by David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van deniessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot,nder Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, Demis Hassabis
summary: they create a convolutional neural network with 13 layers to select moves (given a game position, it outputs a probability distribution over all legal moves, trying to assign higher probabilities to better moves). They train the network on databases of expert matches, save a copy of the trained network as ‘SL’ then train it further by playing it against randomly selected previous iterations of itself. Then they use the history of the move-selecting network playing against itself to generate a new training set consisting of 30 million game positions and the outcome of that game, with each of the 30 million positions coming from a separate game. They use this training set to train a new convolutional neural network (with 13 layers again, i think) to appraise the value of a board position (given a board position, it outputs a single scalar that attempt to predict the game outcome of that board position).
They also train ANOTHER move-predicting classifier called the ‘fast rollout’ policy; the reason for another one is that the fast rollout policy is supposed to be very fast to run, unlike the neural nets. The fast rollout policy is a linear softmax of small pattern features (move matches one or more response features, Move saves stone(s) from capture, Move is 8-connected to previous move, Move matches nakade patterns at captured stone, Move matches 12-point diamond pattern near previous move, move matches 3×3 pattern around candidate move). When a feature is “move matches some pattern”, i don’t understand if they mean that “match any pattern” is the feature, or if each possible pattern is its own feature; i suspect the latter, even though that’s a zillion features to compute. The feature weights of the fast rollout classifier are trained on a database of expert games.
Now they will use three of those classifiers, the ‘SL’ neural network (the saved network that tried to learn which move an expert would have made, before further training against itself), and the board-position-value-predicting network, plus the ‘rollout’ policy.
The next part, the Monte Carlo Tree Search combined with the neural networks, is kinda complicated and i don’t fully understand it, so the following is likely to be wrong. The idea of Monte Carlo Tree Search is to estimate the value of a board position by simulating all or part of game in which both players in the simulation are running as their policy a classifier without lookahead (eg within the simulation, neither player does any lookahead at each step); this simulation is (eventually) done many times and the results are averaged together. This simulation is called ‘rollout’. Each time the Monte Carlo simulation is done, the policy is updated. In this application, the ‘fast rollout’ is used in some parts of this simulation, but not all, because the ‘fast rollout’ policy is fixed after training, but the idea of Monte Carlo Tree Search is that the policy used is updated after each simulation.
In order to take one turn in the real game, the program does zillions of iterations; in each iteration, it simulates a game-within-a-game:
It simulates a game where the players use the current policy, which is represented as a tree of game states whose root is the current actual game state, whose edges are potential moves, and whose nodes or edges are labeled with the current policy’s estimated values for game states (plus a factor encouraging exploration of unexplored or underexplored board states).
When the simulation has visited the parent of a ‘leaf node’ (a game state which has not yet been analyzed but which is a child of a node which is not a leaf node) more than some threshold, the leaf node is added to a queue for an asynchronous process to ‘expand the leaf node’ (analyze it) (the visit-count-before-expansion threshold is adaptively adjusted to keep the queue short). This process estimates the value of the leaf node via a linear combination of (a) the board-position-value-predicting network’s output and (b) the outcome of running a simulation of the rest of the game (a game within a game within a game) with both players using the ‘fast rollout’ policy. Then, the SL neural network is used to give initial estimates of the value of each move from that board position (because you only have to run SL once to get an estimate for all possible moves from that board position, whereas it would take a long time to recurse into each of the many possible successor board positions and run the board-position-value-predicting network for each of these).
Because the expansion of a leaf node (including running SL) is asynchronous, in the mean time (until the node reaches the front of the analysis queue and is analyzed) the leaf node is provisionally expanded and a ‘tree policy’ is used to give a quick estimate of the value of each possible move from the leaf node board state. The tree policy is like the quick rollout policy but with a few more features (move allows stones to be captured, manhattan distance to two previous moves, Move matches 12-point diamond pattern centered around candidate move). The tree policy’s estimate will be replaced when the node reaches the front of the queue and is fully analyzed.
At the end of each iteration, the action values of all (non-leaf) nodes visited are updated, and a ‘visit count’ for each of these nodes is updated.
At the end of all of these iterations, the program actually plays the move that had the maximium visit count in the monte carlo tree search (“this is less sensitive to outliers than maximizing action-value”).
some more details:
- During monte carlo tree search, they also use a heuristic called ‘last good reply’ which is sorta similar to caching.
- the move-predicting networks are for the most part just fed the board state as input, but they also get a computed feature “the outcome of a ladder search”
- because Go is symmetric w/r/t rotations of the board, the move-predicting networks are wrapped by a procedure that either randomly selects a rotation, or runs them for all rotations and averages the results (depending on whether or not the network is being used for monte carlo tree search or not)
Links:
Emerald Therapeutics: they do your experiments for you
They bought a bunch of machines to automate common experimental techniques and wrote software allowing the machines to be remotely programmed over the web. They plan to charge on a per-experiment basis. They are soliciting beta testers for 2015.
Computing with microtubules (Craddock, Tuszynski, Hameroff 2012)
This paper hypothesizes that postsynaptic CaMKII (calcium/calmodulin-dependent protein kinase II) receives synaptic input and then interacts with via phosphorylation, suggesting that memories may be encoded in the microtubules in this way. They note that the size and shape of CaMKII appears to be just right to phosphorylate the hexagonal lattices of tubulin proteins in microtubules. The paper also can “demonstrate microtubule-associated protein logic gates, and show how patterns of phosphorylated tubulins in microtubules can control neuronal functions by triggering axonal firings, regulating synapses, and traversing scale.”. Via ScienceDaily.
Travis J. A. Craddock, Jack A. Tuszynski, Stuart Hameroff. Cytoskeletal Signaling: Is Memory Encoded in Microtubule Lattices by CaMKII Phosphorylation? PLoS Computational Biology, 2012; 8 (3): e1002421 DOI: 10.1371/journal.pcbi.1002421.
