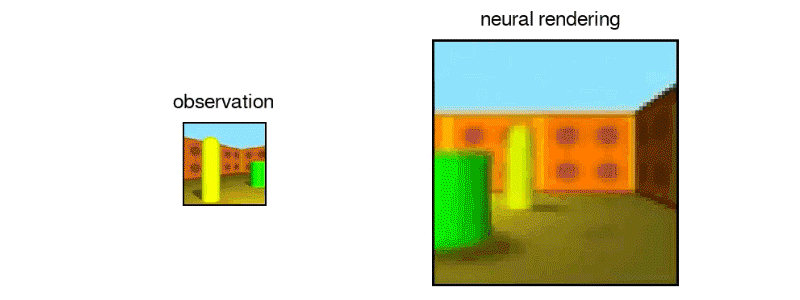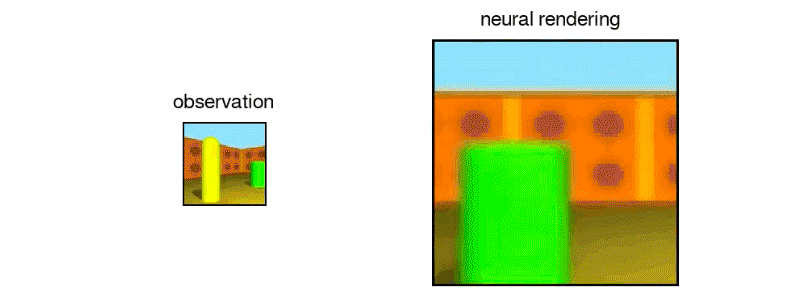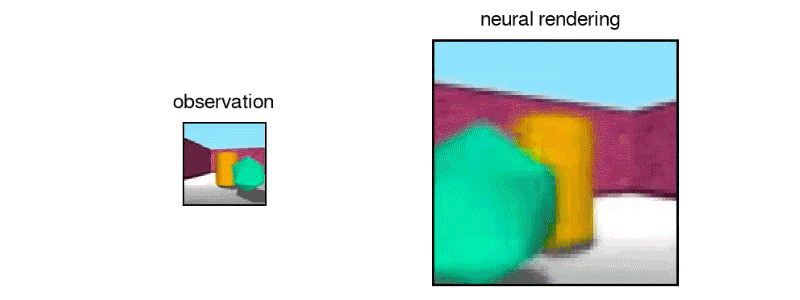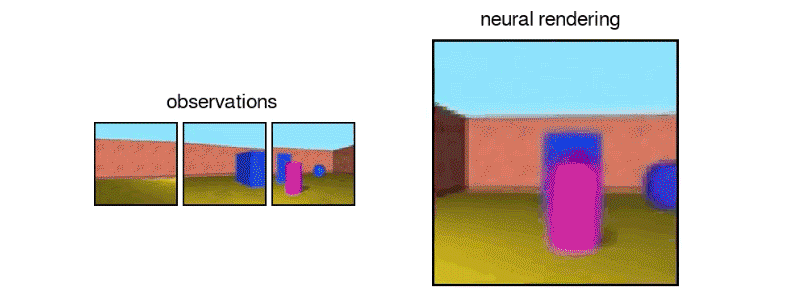
“In this work, published in Science (Open Access version), we introduce the Generative Query Network (GQN), a framework within which machines learn to perceive their surroundings by training only on data obtained by themselves as they move around scenes…The GQN model is composed of two parts: a representation network and a generation network. The representation network takes the agent’s observations as its input and produces a representation (a vector) which describes the underlying scene. The generation network then predicts (‘imagines’) the scene from a previously unobserved viewpoint…The representation network does not know which viewpoints the generation network will be asked to predict, so it must find an efficient way of describing the true layout of the scene as accurately as possible. It does this by capturing the most important elements, such as object positions, colours and the room layout, in a concise distributed representation…The GQN’s generation network can ‘imagine’ previously unobserved scenes from new viewpoints with remarkable precision. When given a scene representation and new camera viewpoints, it generates sharp images without any prior specification of the laws of perspective, occlusion, or lighting. The generation network is therefore an approximate renderer that is learned from data”
https://deepmind.com/blog/neural-scene-representation-and-rendering/
Neural scene representation and rendering by S. M. Ali Eslami*,†, Danilo Jimenez Rezende†, Frederic Besse, Fabio Viola, Ari S. Morcos, Marta Garnelo, Avraham Ruderman, Andrei A. Rusu, Ivo Danihelka, Karol Gregor, David P. Reichert, Lars Buesing, Theophane Weber, Oriol Vinyals, Dan Rosenbaum, Neil Rabinowitz, Helen King, Chloe Hillier, Matt Botvinick, Daan Wierstra, Koray Kavukcuoglu, Demis Hassabis.
Click to access Neural_Scene_Representation_and_Rendering_preprint.pdf
